Pengenalan Data Science
Apa itu Data Science?
Data Science merupakan suatu bidang ilmu yang menggabungkan beberapa disiplin ilmu yang kemudian dapat digunakan untuk mengekstraksi sebuah ilmu dan insight dengan mempelajari pattern data yang ada baik data yang terstruktur maupun yang tidak terstruktur.
Dalam bisnis, Data Science kerap digunakan untuk menggali berbagai insight baru yang berpotensi mampu meningkatkan performa bisnis perusahaan melalui sekumpulan data besar dan akan terus berkembang yang diproduksi oleh entitas bisnis itu sendiri.
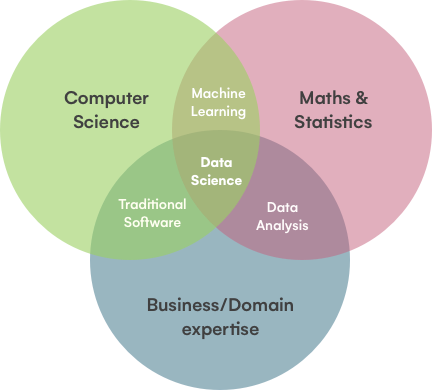
Data Science sendiri sejatinya menggabungkan metode saintifik, matematika, statistika, ilmu komputer, domain knowledge, serta storytelling untuk menggali insight yang terdapat dalam kumpulan data. Jika digambarkan kedalam diagram, kurang lebih akan menjadi seperti berikut relasi antar disiplin ilmunya.
Mudahnya, Data Science merupakan seperangkat metode untuk mengambil ribuan data yang saat ini tersedia, dan menggunakannya untuk menarik kesimpulan. Di era saat ini, data ada dimana-mana di sekitar kita. Setiap like, klik, email, gesekan kartu kredit, bahkan tweet merupakan sebuah data baru yang bisa digunakan untuk menggambarkan kejadian saat ini atau bahkan memprediksi masa depan dengan lebih baik.
Aplikasi Data Science dalam Kehidupan Sehari-hari
Sebenarnya, tempat kita hidup saat ini sudah mulai memasuki data-driven world. Dimana banyak hal disekitar kita telah memanfaatkan data untuk menjalankan aktivitasnya. Bahkan ada sebuah istilah "data is the new oil" yang artinya banyak hal yang bisa kita lakukan jika kita memiliki data.
Data mampu mendeskripsikan keadaan kita saat ini, misalnya konsumsi listrik rumah. Melalui sebuah dashboard, data tersebut mampu menyederhanakan laporan penggunaan listrik yang sebelumnya sangat memakan waktu. Contoh lainnya, bagi perusahaan yang memberikan pinjaman kepada masyarakat, data dapat digunakan untuk mendeteksi adanya kejadian anomali seperti fraud yang dapat mengakibatkan perusahaan menjadi rugi.
Jika kita memiliki data di masa lampau seperti data riwayat pemutaran film di Netflix, maka kita juga akan mampu memberikan rekomendasi film yang mungkin disukai pula oleh pengguna. Sehingga hal tersebut secara tidak langsung mampu menjaga pengguna untuk menjadi pelanggan setia Netflix.
Tidak hanya itu, dengan data, kita juga bahkan bisa memprediksi kejadian di masa mendatang seperti ukuran populasi sebuah negara. Atau bahkan sesimpel prediksi nilai ujian akhir seorang siswa berdasarkan nilai tugas, ulangan harian, serta ulangan tengah semesternya.
Tools yang Perlu Dikuasai
Sebagai seorang Data Scientist, kita perlu menguasai beberapa tools yang cukup umum dan sering digunakan dalam proyek sehari-hari, agar pekerjaan kita menjadi lebih efisien. Beberapa tools tersebut diantaranya.
Python / R
Python atau R merupakan bahasa pemrograman yang sangat umum di bidang Data Science. Keduanya dapat membantu kita dalam hal pengolahan dan eksplorasi data. Dengan menggunakan bahasa pemrograman, kita bisa memanfaatkan library yang tersedia untuk menunjang pekerjaan kita. Dan dukungan library untuk kedua bahasa tersebut sudah cukup banyak, sehingga kita akan bisa lebih fleksibel dan efisien dalam melakukan pekerjaan.
Structured Query Language (SQL)
SQL merupakan sebuah bahasa standar pada database relasional. Sebagai seorang Data Scientist, kita perlu menguasai tools ini agar memudahkan kita dalam mengakses data yang telah disediakan untuk kita. Umumnya, kita akan sering bekerja sama dengan Data Engineer — seseorang yang bertugas untuk mengumpulkan data. Seorang Data Engineer akan menyimpan data-data tersebut dalam sebuah database, oleh karena itu kita sebagai Data Scientist — seseorang yang akan mengonsumsi data tersebut, perlu menguasai tools SQL ini.
Busines Intelligence Tools (Power BI, Tableau, Google Data Studio, dll)
Business Intelligence (BI) Tools merupakan software yang dapat membantu kita untuk melakukan eksplorasi dan visualisasi data lebih cepat tanpa programming. Seorang Data Scientist, tidak selalu harus melakukan programming untuk menyelesaikan pekerjaannya. Misalnya pada fase eksplorasi dan visualisasi, pada beberapa kasus mungkin jika dikerjakan melalui programming akan jauh lebih memakan waktu, sehingga akan jauh lebih efisien jika proses tersebut dilakukan dengan menggunakan BI Tools ini.
Tidak hanya itu, terkadang seorang Data Scientist juga dituntut untuk melaporkan hasil analisisnya melalui sebuah dashboard. Nah, untuk membuat dashboard tersebut BI Tools inilah jagoannya.
Machine Learning Libraries (Scikit-Learn, XGBoost, LightGBM, dll)
Machine Learning (ML) Libraries, sesuai judulnya tools ini berguna untuk membantu kita dalam membuat model ML. Ada banyak ML Libraries yang sudah tersedia, kita pun tidak diharuskan menguasai semuanya. Yang terpenting adalah bagaimana kita memahami proses atau cara kerja dibalik model tersebut, sehingga kita bisa dengan mudah menentukan manakah model yang paling sesuai untuk proyek Data Science kita.
Dari sekian banyak library yang ada, Scikit-Learn menjadi pilihan banyak orang untuk memulai. Dokumentasi yang dimiliki cukup lengkap dan mudah dipahami, API yang tersedia juga telah terstandarisasi dan terbilang mudah diingat, menjadikannya sangat cocok sebagai pijakan awal.
Deep Learning Libraries (Tensorflow, Kearas, PyTorch, MXNet, dll)
Deep Learning (DL) Libraries, merupakan tools yang biasa digunakan untuk melakukan tugas-tugas yang jauh lebih berat dari yang mampu dilakukan oleh ML Libraries. Umumnya, Deep Learning digunakan untuk mengolah data yang amat sangat banyak, karena algoritma dan teknologinya yang sudah disesuaikan menjadikannya cocok untuk digunakan dalam tugas yang lebih spesifik. Salah satu contoh penerapan Deep Learning yang sering kita temui adalah Face Detection (pengenalan wajah).
CRISP-DM
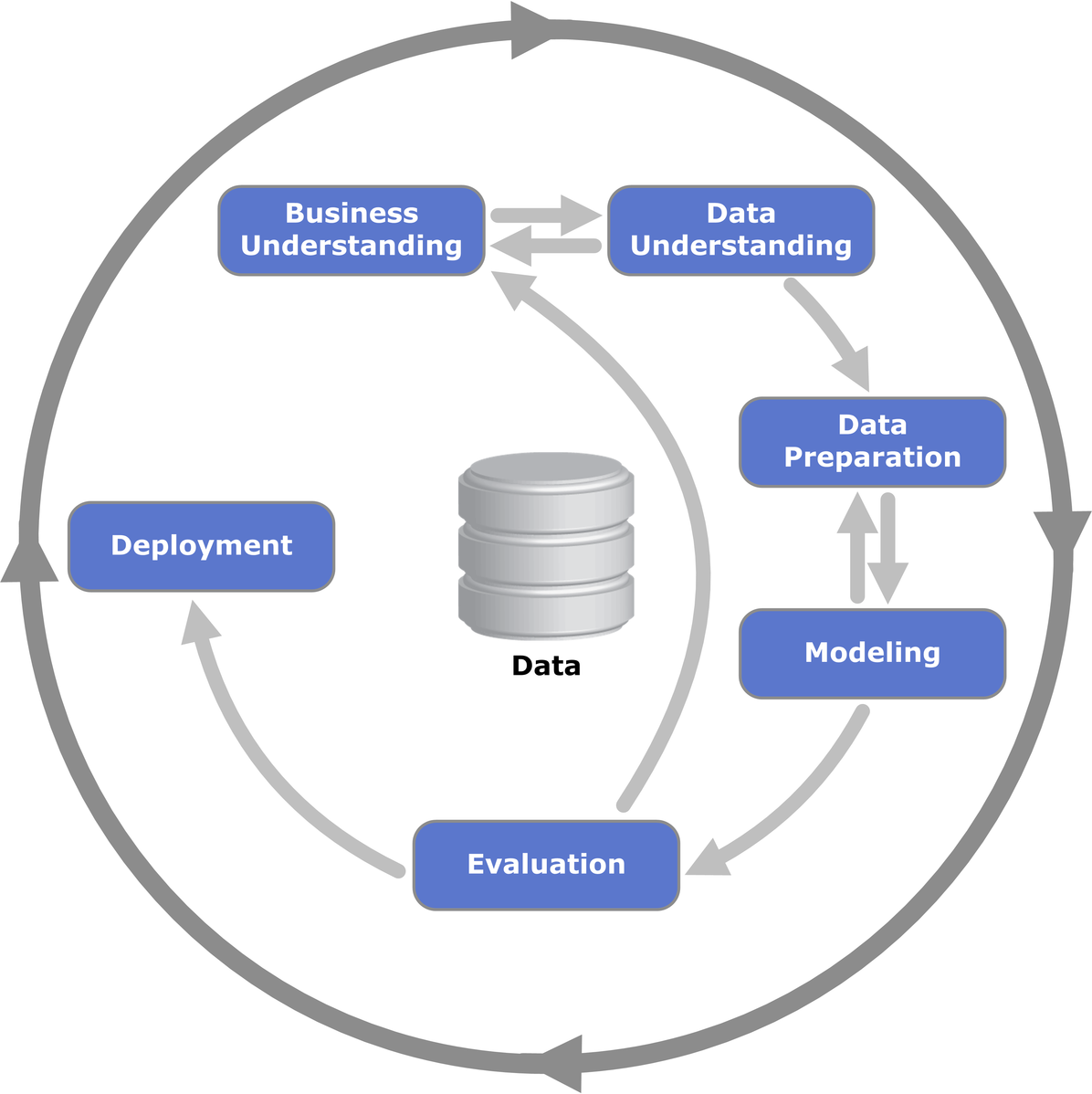
CRISP-DM, singkatan dari CRoss Industry Standard Process for Data Mining merupakan sebuah framework standar di bidang Data Science. Framework ini terdiri dari 6 alur kerja, yaitu Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, dan Deployment. Seluruh proses tersebut berjalan secara iteratif dan tidak menutup kemungkinan untuk kembali ke tahap-tahap sebelumnya. Karena sejatinya, proyek data science bukan hanya sekedar memuat data kemudian membuat model saja. Lebih besar dari itu, kita wajib paham dengan permasalahan apa yang hendak diselesaikan, dimana harus mencari sumber data, bagaimana mempersiapkan data dengan baik sebelum diinput ke model, hingga memonitor bagaimana performa model tersebut saat digunakan oleh pengguna.
Business Understanding
Tahap pertama dalam proyek data science adalah Business Understanding. Di tahap ini kita harus memahami permasalahan yang akan diselesaikan, menentukan kebutuhan dan ketersediaan resource, dan menentukan kriteria kesuksesan proyek. Bisa dibilang tahapan ini merupakan pondasi dasar proyek kita. Karenanya, kita harus benar-benar memahami terlebih dahulu apa yang ingin diselesaikan sebelum beranjak ke tahapan berikutnya.
Data Understanding
Setelah paham dengan apa yang hendak kita selesaikan, tahap berikutnya adalah Data Understanding. Disini kita mulai mencari sumber data yang cocok, valid, dan reliable dengan tujuan kita. Tidak jarang pula, kadang kita perlu kembali ke tahap sebelumnya untuk memastikan atau memahami kembali permasalahan apa yang sedang kita selesaikan. Hal ini dilakukan agar kita bisa semakin spesifik dalam mencari data.
Jika data sudah terkumpul, maka sebelum lanjut ke tahapan berikutny kita perlu melakukan eksplorasi terhadap data. Kita perlu memastikan apakah datanya lengkap? Apakah terdapat data outlier didalamya? Bahkan mungkin juga kita perlu melihat distribusi datanya, apakah imbalanced? Dari sinilah kita bisa menentukan secara tepat action apa yang akan kita lakukan di tahap berikutnya.
Data Preparation
Nah, di tahap inilah kita mengeksekusi hasil temuan-temuan kita pada tahap sebelumnya. Di tahap Data Preparation ini kita akan mempersiapkan data sedemikian sehingga data menjadi bersih dan rapi.
Disini kita melakukan pemilihan data seperti variabel mana saja yang akan digunakan untuk modeling nantinya. Menggabungkan data dari beberapa sumber menjadi satu set data yang lebih bermakna sehingga mampu memberikan insight yang lebih banyak misalnya.
Ada istilah "Garbage In Garbage Out" yang secara singkat berarti bahwa kita harus memastikan bahwa data yang diberikan pada model adalah data yang bersih. Karena jika tidak, model kita akan sangat memungkinkan memiliki performa yang buruk.
Modeling
Setelah data dibersihkan, inilah saatnya kita bermain-main dengan berbagai algoritma machine learning. Disini kita akan melakukan berbagai eksperimen terhadap berbagai macam algoritma untuk menemukan model mana yang akan memiliki performa terbaik. Dalam menentukan performa model, nantinya kita akan dekat dengan Evaluation metrics. Evaluation metrics ini pun banyak jenisnya, dan berbeda-beda penggunaannya sesuai dengan task yang dihadapi.
Evaluation
Di tahap ini, kita mulai melakukan evaluasi antara model dengan bisnis atau permasalahan yang kita hadapi diawal. Kita pastikan kembali, apakah model yang dibangun sudah mampu menjawab permasalahan kita? Apakah seluruh proses sudah dilakukan dengan benar dan tidak ada yang terlewat?
Jika dipastikan semua sudah beres maka berikutnya adalah saatnya kita melakukan Deployment.
Deployment
Di tahap paling akhir ini, kita akan men-deploy sebuah model yang sudah kita buat ke production environment. Dimana model kita akan dapat diakses secara langsung oleh end-user. Pada tahap ini, kita harus melakukan monitoring terhadap performa model dari hari-ke-hari. Karena seiring bertambahnya waktu, tentunya data yang dihasilkan juga semakin banyak, dan hal tersebut sangat berpotensi membuat model kehilangan performa terbaiknya. Oleh karena itu, pada saat performa model mulai mengalami penurunan, ada baiknya kita melakukan peninjauan kembali dan melakukan improvement.
Last updated